Deploying Containers with Docker, GCP Cloud Run and Flask-RESTful
Deploying Containers with Docker, GCP Cloud Run and Flask-RESTful
Serving up an API to access data from Google BigQuery
Photo by Ian Taylor on Unsplash
These days, data science practitioners find themselves relying on cloud platforms more and more, either for data storage, cloud computing, or a mix of both. This article will demonstrate how to leverage Cloud Run in GCP to access a dataset stored on Google BigQuery, apply a quick transformation, and present the result back to users through a Flask-RESTful API.
Intro — GCP Cloud Run, Containers vs VMs
Cloud Run is a service that allows you to construct and deploy containers that can be accessed via HTTP requests. Cloud Run is scalable and abstracts away infrastructure management so you can get things up and running quickly.
What is a container you ask? A simple way to think about containers is that they are similar to a Virtual Machine (VM), but much smaller in scale and scope.
With a VM, you typically have a virtual version of an entire OS running (such as a Windows PC running a Linux VM through something like VirtualBox.) This Linux VM will typically have a GUI, a web browser, word processing software, IDEs and a whole host of software accompanying it.
With containers however, you can have the minimal amount of software necessary to perform your desired task, making them compact and efficient, easy to create, destroy and deploy on the fly. For example, the container in this article will just have Python 3.8 installed and nothing else.
Cloud Run is well-suited to deploying stateless containers. For a good insight into stateful vs stateless containers, take a look at this article.
Getting Started
The public dataset on BigQuery we will be looking at is the bigquery-public-data.usa_names.usa_1910_2013 dataset:
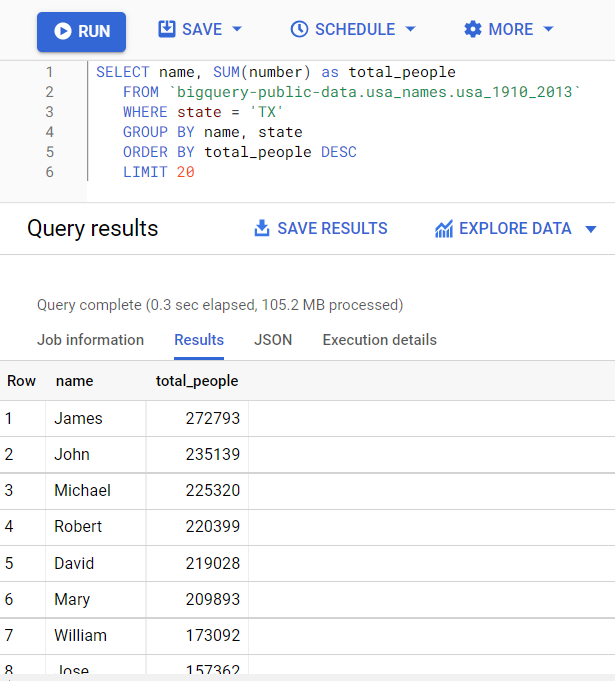
Querying to get total counts of first names.
Before getting started, you will need to create:
- A Project on GCP,
- a service account and a service account key.
For a guide on how to quickly do so, check out the BigQuery API docs. Once you have created a service account, you can create and download a .json service account key, which is used to authenticate you when trying to access BigQuery data through the BQ API.
Step 1: Google Cloud Shell
Access Google Cloud Shell and click ‘Open Editor’. You should see something like this:
Cloud Shell Editor — Notice ‘Cloud Code’ in bottom left corner.
Next click ‘Cloud Code’ in the bottom left corner:
This will bring up a menu of options. Select ‘New Application’:
Then from the following options select ‘Cloud Run Application’ → ‘Python (Flask) : Cloud Run’. This gives you the sample Flask-based ‘Hello World’ application for Cloud Run that we will build on to access our BigQuery dataset. You should now have something like this:
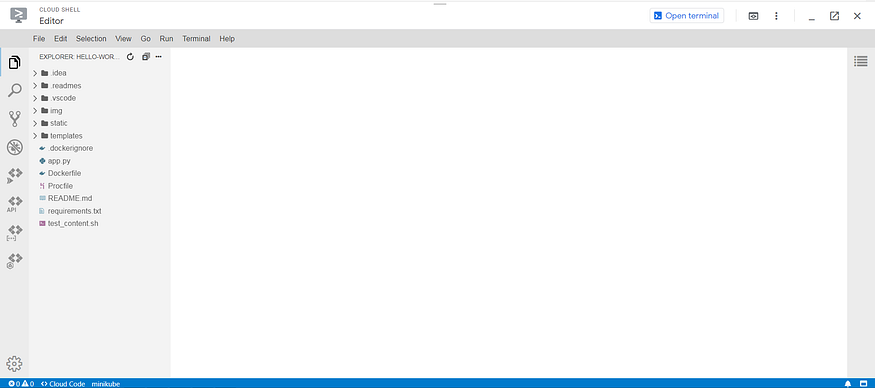
Hello World sample application
The next steps will be changing the provided app.py and Dockerfile, as well as adding some code of our own to access BigQuery.
Step 2: Building the container with Docker
The first step is to slightly edit the existing Dockerfile to specify how our container will be created. Replace the existing Dockerfile code with:
# Python image to use.
FROM python:3.8
# Set the working directory to /appWORKDIR /app
# copy the requirements file used for dependencies
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
RUN pip install flask-restful
RUN pip install --upgrade google-cloud-bigquery
RUN pip install --upgrade gcloud
RUN pip install pandas
# Copy the rest of the working directory contents into the container at /app
COPY . .
# Run app.py when the container launches
ENTRYPOINT ["python", "app.py"]
This Dockerfile will:
- Build a container from the official Python 3.8 image
- Set the working directory of the container
- Install the packages in the existing requirements.txt file
- Install the extra packages necessary (these could instead be added to the existing requirements.txt file if one wished)
- Copy other existing files in the working directory to the container’s working directory (his includes our service account key)
- Run app.py when the container launches
Step 3: Starting the Flask app with app.py
Replace the code in the existing app.py with:
import os
import requests
import bqfrom flask import Flask
from flask_restful import Resource, Apiapp = Flask(__name__)
api = Api(app)class QueryData(Resource):
def get(self):
return bq.run_()api.add_resource(QueryData, '/')if __name__ == '__main__':
server_port = os.environ.get('PORT', '8080')
app.run(debug=True, port=server_port, host='0.0.0.0')
Flask-RESTful uses Resource objects to easily define HTTP methods (see the docs for more info). Above we define a Resource to get the results of our bq.py Python script which queries, sorts and returns the data. (It’s possible to create a number of resources and add them to the API using the .add_resource() method.)
Step 4: BigQuery API Python code
Below is the code file that will access the bigquery-data.usa_names.usa_1910_2013 dataset:
bq.py
def run_():
import os
import pandas as pd from google.cloud import bigquery
from google.oauth2 import service_account key_path = "./your_key.json" credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
) client = bigquery.Client(credentials=credentials) query = """
SELECT name, SUM(number) as total_people
FROM `bigquery-public-data.usa_names.usa_1910_2013`
WHERE state = 'TX'
GROUP BY name, state
ORDER BY total_people DESC
LIMIT 20
"""
query_job = client.query(query)
counts = []
names = []
for row in query_job:
names.append(row["name"])
counts.append(row["total_people"])
# put names and name counts in a dataframe and sort #alphabetically, to simulate operating on data with a model
results = {'Names': names, 'Name Counts': counts}
df = pd.DataFrame.from_dict(results) # convert to DataFrame
df = df.sort_values(by=['Names']) # sort alphabetically
df = df.to_dict(orient='list') # convert to dictionary format
return df
Add this code to a new file name bq.py in the same directory as app.py and the Dockerfile:

bq.py
Breakdown of bq.py:
This section will allow us to authenticate and access BigQuery to fetch our data:
from google.cloud import bigquery
from google.oauth2 import service_account
key_path = "./your_key.json"credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
client = bigquery.Client(credentials=credentials)
Note that key_path = “./your_key.json” must be changed to the name of your downloaded json service account key from earlier. To import your downloaded key from your computer’s downloads folder into the Cloud Shell editor, simply drag and drop the file into your browser window:
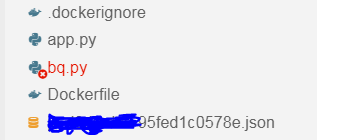
Service account key now in Cloud Shell project.
The next section contains the query for our desired data:
query = """
SELECT name, SUM(number) as total_people
FROM `bigquery-public-data.usa_names.usa_1910_2013`
WHERE state = 'TX'
GROUP BY name, state
ORDER BY total_people DESC
LIMIT 20
"""
query_job = client.query(query)
The remaining code simply applies sorting to the two data columns, sorting the columns according to the alphabetical order of the ‘Name’ column:
counts = []
names = []
for row in query_job:
names.append(row["name"])
counts.append(row["total_people"])
# put names and name counts in a dataframe and sort #alphabetically, to simulate operating on data with a model
results = {'Names': names, 'Name Counts': counts}
df = pd.DataFrame.from_dict(results) # convert to DataFrame
df = df.sort_values(by=['Names']) # sort alphabetically
df = df.to_dict(orient='list') # convert to dictionary format
return df
The data must be returned in a json compatible format for use with Flask-RESTful, which is why we return the data in dictionary format.
Final Step — Deploy Container with Cloud Run!
Finally, we can deploy our service to the web. Deploying with Cloud Run will generate a link that will allow access to the result of our data transformation.
Once again, select ‘Cloud Code’ in the bottom left corner of the Cloud Shell Editor. This time click ‘Deploy to Cloud Run’ :
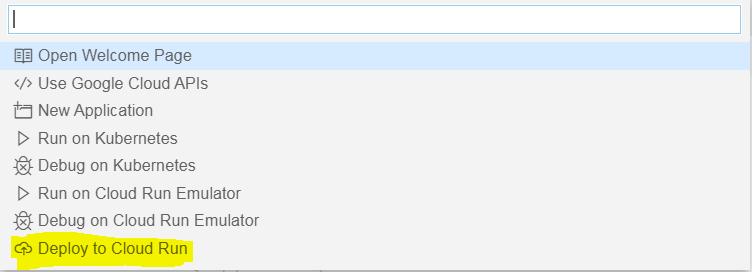
Follow the steps to create a service, choose a region, allow unauthenticated invocations, and a build environment (either local or with Cloud Build). When you are ready, click Deploy! You can click ‘Show Detailed Logs’ to view the steps of the build and deployment taking place.
When the container has finished building, click the provided link:

This link opens a new tab to our final result — the queried BQ data with sorting applied!

The two data columns have been sorted, according to the alphabetical order of the ‘Name’ column! While this is a simple operation, the potential for more complex workflows exists. Instead of sorting data, you could apply a trained machine learning model to make predictions and return the results through an API instead. Adding a nicer design to the page as well would help readability.
As a side note, it is not considered best practice to have service account keys sitting in storage, there are other alternative authentication methods available for GCP. Also, keep an eye on billing for GCP products, the public BQ datasets can be queried up to 1TB for free but it is worth deactivating projects if you are not using them long term.
I hoped this article was of use to you. If you liked this story, please consider following me on Medium.
Find me on LinkedIn: https://www.linkedin.com/in/mark-garvey/